NeurIPS用AI检测,说我的论文是AI生成的
NeurIPS用AI检测,说我的论文是AI生成的NeurIPS 2026 正在用 AI 检测器来判定「论文投稿是否使用 AI」,并作为拒稿的重要依据。
来自主题: AI资讯
7924 点击 2026-06-04 16:39
 搜索
搜索
NeurIPS 2026 正在用 AI 检测器来判定「论文投稿是否使用 AI」,并作为拒稿的重要依据。

过去十年,压缩在 CV 学术圈一直是个边缘方向——做生成、做大模型才是显学。但 SparcAI 的两位95后创始人各自做了多年压缩,然后在同一间 NTU 实验室相遇,两年后发布了 Sparc3D。模型 demo 上线当日冲上 HuggingFace Trending 榜首,论文被 NeurIPS 2025 录用。如今他们创办了 SparcAI,目标是一家世界模型公司。

近日,在全球人工智能领域最具影响力的顶级学术会议 NeurIPS(神经信息处理系统大会)上, 清华大学和蚂蚁数科联合提出了一种名为 Dual-Flow 的新型对抗攻击生成框架。

在深入技术细节之前,我们先用一张漫画来直观理解 COIDO (Coupled Importance-Diversity Optimization) 解决的核心问题与方案:正如钟离在漫画中所言,面对海量视觉指令数据的选择任务,传统方法需要遍历全部数据才能进行筛选造成大量「磨损」(高昂计算成本)。同时在面对数据重要性和多样性问题时,传统方法往往顾此失彼。

不久前,NeurIPS 2025 顺利举办,作为人工智能学术界的顶级会议之一,其中不乏学术界大佬的工作和演讲。

NeurIPS 2025见证了历史性的分流:清华大学以微弱差距逼近谷歌,中国AI完成了从数量堆叠向底层架构创新的「质变」突围。在圣地亚哥与墨西哥城的双会场之间,签证壁垒切割了物理空间。这是一场关于算力、人才与技术定义权的「双城记」。

两项关于大模型新架构的研究一口气在NeurIPS 2025上发布,通过“测试时训练”机制,能在推理阶段将上下文窗口扩展至200万token。两项新成果分别是:Titans:兼具RNN速度和Transformer性能的全新架构;MIRAS:Titans背后的核心理论框架。
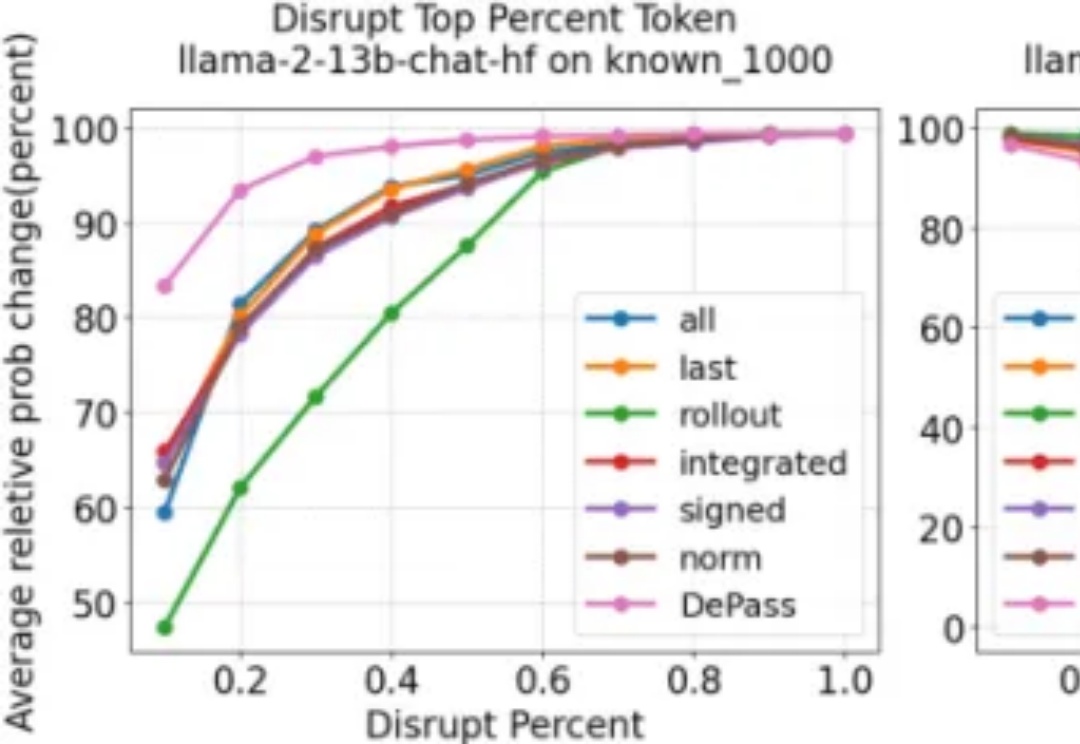
随着大型语言模型在各类任务中展现出卓越的生成与推理能力,如何将模型输出精确地追溯到其内部计算过程,已成为 AI 可解释性研究的重要方向。然而,现有方法往往计算代价高昂、难以揭示中间层的信息流动;同时,不同层面的归因(如 token、模型组件或表示子空间)通常依赖各自独立的特定方法,缺乏统一且高效的分析框架。
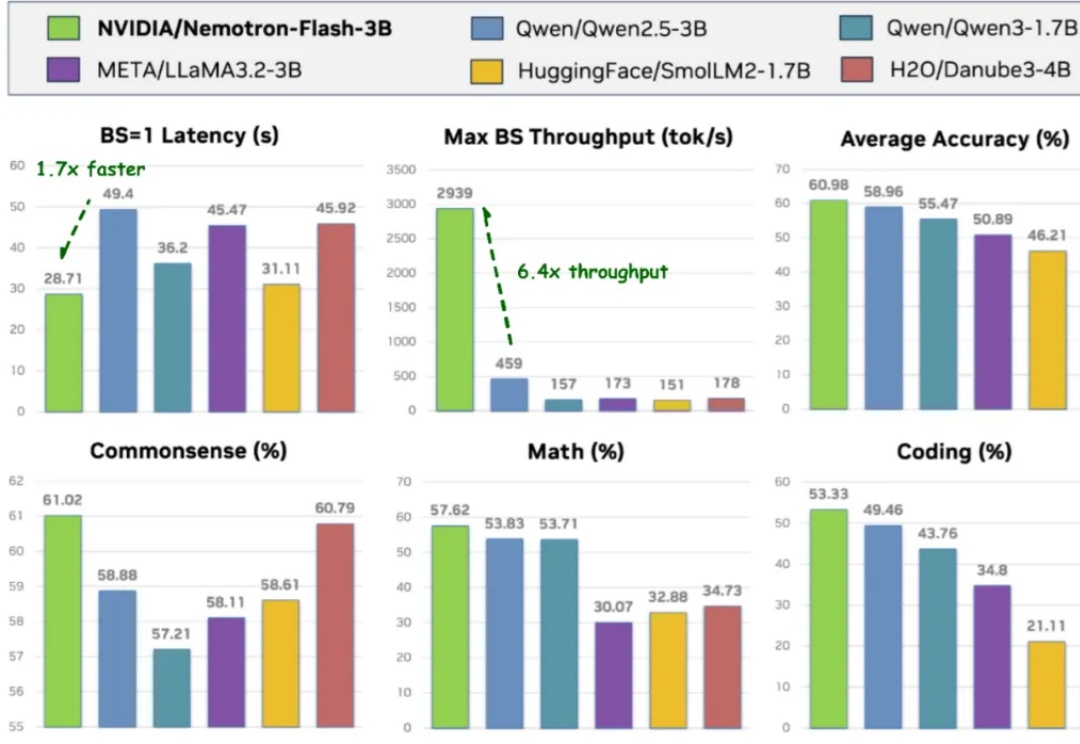
导读 过去两年,小语言模型(SLM)在业界备受关注:参数更少、结构更轻,理应在真实部署中 “更快”。但只要真正把它们跑在 GPU 上,结论往往令人意外 —— 小模型其实没有想象中那么快。

在大语言模型(LLM)的研究浪潮中,绝大多数工作都聚焦于优化模型的输出分布 —— 扩大模型规模、强化分布学习、优化奖励信号…… 然而,如何将这些输出分布真正转化为高质量的生成结果 —— 即解码(decoding)阶段,却没有得到足够的重视。